Transition Sampling Workflow¶
The transition sampling package (based on the aimless shooting likelihood maximization algorithm) works in three sequential phases to find collective variables that describe the transitory dividing surface between two or more stable basins. These CVs are optimized as a linear combination, which can then be interpreted as a reaction coordinate. A summary is below:
Generate new configurations near the dividing surface (Aimless Shooting)
From initial starting guess configuration(s), generate more configurations near the dividing surface by running molecular dynamics simulations. This is by far the most computationally expensive part of the workflow, but only has to be done once. If more configurations are needed for better statistics, this can be picked up where it left off, meaning more samples can be added at a later point.
Calculate given collective variables for the configurations
From the generated configurations, calculate collective variables (colvars or CVs) for each. This step is fast and flexible using PLUMED.
Likelihood Maximization
From the calculated CVs, perform likelihood maximization over them to find the linear combination of CVs that best explains which shooting points were accepted (more likely on the dividing surface) vs rejected (less likely on the dividing surface). This final step is on the order of a couple of minutes to run, depending on the number of samples and CVs.
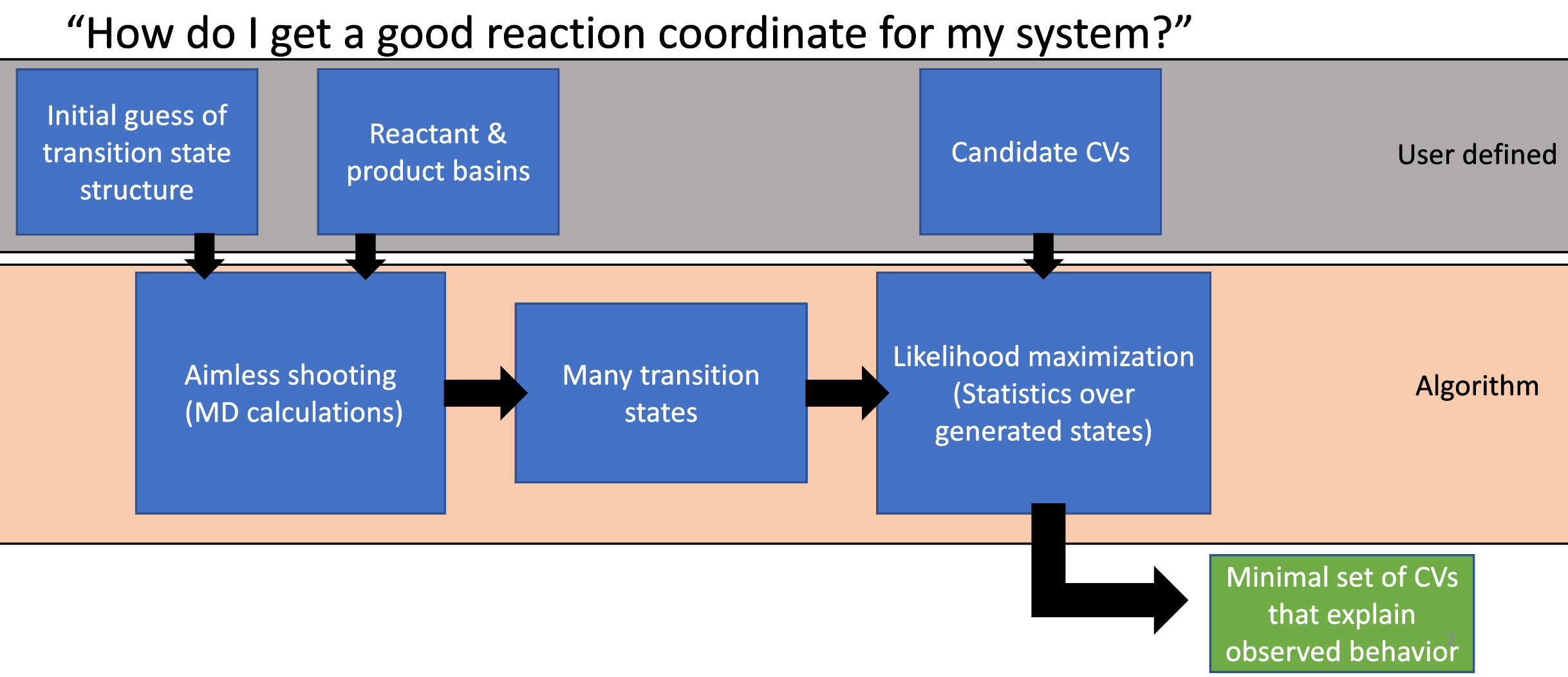
Aimless shooting only has to be performed once to generate a sufficient set of configurations near the dividing surface (shooting points). After they are generated, CV calculation can be performed with any CVs defined in PLUMED quickly and maximized again, allowing the user to quickly search through many potential CV combinations without performing expensive MD.
Aimless Shooting¶
For exact specifications, refer to the original paper by Peters and Trout, 10.1063/1.2234477
Generation of shooting points¶
Aimless shooting takes an initial (or multiple) configuration that are guessed to be near the transition state, or on the dividing surface between two or more stable basins. Velocities are randomly generated from the Maxwell-Boltzmann distribution and two trajectories are launched in parallel
One with the initial velocities set as generated. This is the forward trajectory
One with the generated velocities flipped (multiplied by -1). This is the reverse trajectory
These simulations are run until committing to one of the defined basins, or until completing the number of steps specified in the MD parameters. If the two trajectories commit to different basins (or different categories of basins in the case of multiple reactant or product states), this shooting point is considered as accepted. Otherwise, its said to be rejected. The core ideas of aimless shooting are that
An accepted shooting point is more likely to be on the dividing surface than a rejected shooting point
If we take an accepted shooting point and perturb its configuration slightly, it’s likely to result in another accepted shooting point. I.e., it should remain close to the dividing surface because the perturbation was small.
Using these principles, we generate more accepted shooting points by randomly perturbing an already accepted shooting point along it’s forward or reverse trajectory by \(\Delta t\), where \(\Delta t\) is a time values that’s a small proportion of the overall reaction time. The specifics of this are defined in the above paper, but it essentially results in trying the new shooting point randomly from one of the configurations in \(-2\Delta t \ -\Delta t, \ 0, \ +\Delta t, \ +2\Delta t\) from the previous accepted shooting point’s forward and reverse trajectories. It’s therefore possible that the old shooting point could be chosen again as the new one.
If a shooting point is not accepted, it’s not clear what step should be taken next. If a new shooting point is rejected,
we try resampling the velocities up to n_vel_tries. If one of these is accepted, the shooting point is immediatley
considered accepted. If all of these are rejected, the shooting point is entirely rejected. The results of each shooting
are considered because they are still useful in the likelihood maximization. For example, a shooting point that is rejected
3 times and accepted on the 4th time indicates that it is further from the dividing surface than one that immediately accepts.
When a shooting point is entirely rejected, it is again unclear what to do. In our case, we keep a list of all shooting
points that have ever been accepted and randomly select one of them to restart with after a complete rejection of a point.
There’s then an additional parameter n_state_tries that controls how many total rejections can happen in a row before
totally failing and exiting.
Initial starting¶
A directory of initial starting guesses (containing one or more .xyz files that store coordinates in Å) is used to
‘seed’ the aimless shooting processes. These should be points you believe to be on the dividing surface. Each point will
try to be accepted up to n_vel_tries by resampling velocities. If all of these attempts are rejected, the point
will be considered rejected. At least one of your starting guesses needs to be accepted in order to proceed, otherwise the
program will exit.
Parallel shootings¶
One instance of aimless shooting can only run two MD simulations at a time (forwards and reverse) because new shooting points are generated sequentially. If you have more computational resources, you can run multiple aimless shootings independently in parallel, and their configurations are recombined at the end. For example, you could run 4 parallel aimless shootings to have 8 MD simulations running simultaneously. All parallel shootings are started from the same initial configurations, but will diverge since velocities are randomly generated.
Each parallel instance will generate its own pair of result files, as well as one cumulative combined pair of result files.
Basins¶
One or more stable basins are defined using PLUMED’s
COMMITTOR directive in a plumed.dat file.
This allows the flexibility to define any basin in terms of existing PLUMED CVs, while also ending a simulation upon
reaching one of these basins.
Aimless shooting outputs¶
Our aimless shooting results in two files: a .csv and a .xyz.
.xyzstores coordinates of attempted shooting points in Å appended to one another. Each velocity resampling records to this file, so it’s not uncommon to see multiple of the same configuration in a row.
.csvEach row corresponds to the configuration on the
.xyzfile and stores metadata about it. It stores if that configuration was considered to be accepted, the integer of the basin the forward trajectory committed to, the basin the reverse trajectory committed to, and the PBC box size (in Å) of the configuration. If a trajectory did not commit,Noneis stored.
Collective Variable Calculation¶
Given a pair .xyz and .csv result files from aimless shooting, PLUMED can be used to calculate any number of
configurational collective variables for each entry in the .xyz file. Simply define all the collective variables to
be calculated in a plumed.dat and provide the path to the plumed binary, and the standard PLUMED output COLVAR
file will be generated.
Again, this can be repeated with any combination of different CVs over one aimless shooting result pair.
Likelihood Maximization¶
With the desired set of calculated collective variables and the corresponding result .csv from aimless shooting,
likelihood maximization can be performed. Here we find a linear combination of a subset of the given collective variables
that best represents the reaction coordinate for this system.
Individual optimization of a set of CVs¶
For a single optimization of all CVs in a set, we perform the following:
The reaction coordinate \(r\) is linear combination of \(m\) collective variables \(\mathbf{x}\) defined for a shooting point with weights \(\boldsymbol{\alpha}\) plus a constant \(\alpha_0\):
The probability that a shooting point is on a transition path (TP) is chosen to be modeled as a non-gaussian bell curve and is given by:
This probability is maximized for CVs of accepted shooting points and minimized for rejected shooting points by optimizing \(\boldsymbol{\alpha}\), \(\alpha_0\), and \(p_0\) and considering each point to be drawn i.i.d.
The log-likelihood \(l\) is evaluated, as it has an equivalent solution.
This is a constrained (\(p_0 \in (0, 1]\)) non-convex optimization, so we use basin-hopping to perform a series of local
optimizations in attempt to find a global maximum, the number of iterations for which can be set with n_iter.
Optimization of all candidate CVs¶
It’s likely that some candidate CVs will contribute more to the likelihood than others. We don’t want to include CVs that don’t significantly increase it - we want to find the minimal set of CVs that make a good reaction coordinate. To facilitate this, we start by evaluating the above objective function with only one CV in the available set. We take the maximum value as the best combination for length \(i\), (where \(i=1\) initially). Then:
Evaluate the objective function of each combination of length \(i+1\). Take the best value.
If the best value for length \(i+1\) increased by more than \(0.5 \ln (N)\), where \(N\) is the number of sample shooting points:
Then repeat with \(i=i+1\) for all combinations of the next highest length
Otherwise, this is our optimal solution
Likelihood maximization results¶
The result file for likelihood maximization is .csv that stores the results of all maximized combinations, not just the
final maximum. It has columns # of CVs, obj. func. value, p0, alpha0, <one column for the weight of each CV>.
For CVs that are not included in a row’s optimization, their value is empty or nan